
一直以来想搭建一个友情链接朋友圈,这样在自己的网站上就很能方便的查看朋友圈正在干嘛。󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
以前看到过一个基于hexo的友链朋友圈项目,但是自己部署后还是失败了,最近看到obaby的博客实现了这个功能,让我顿时有了兴趣。󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
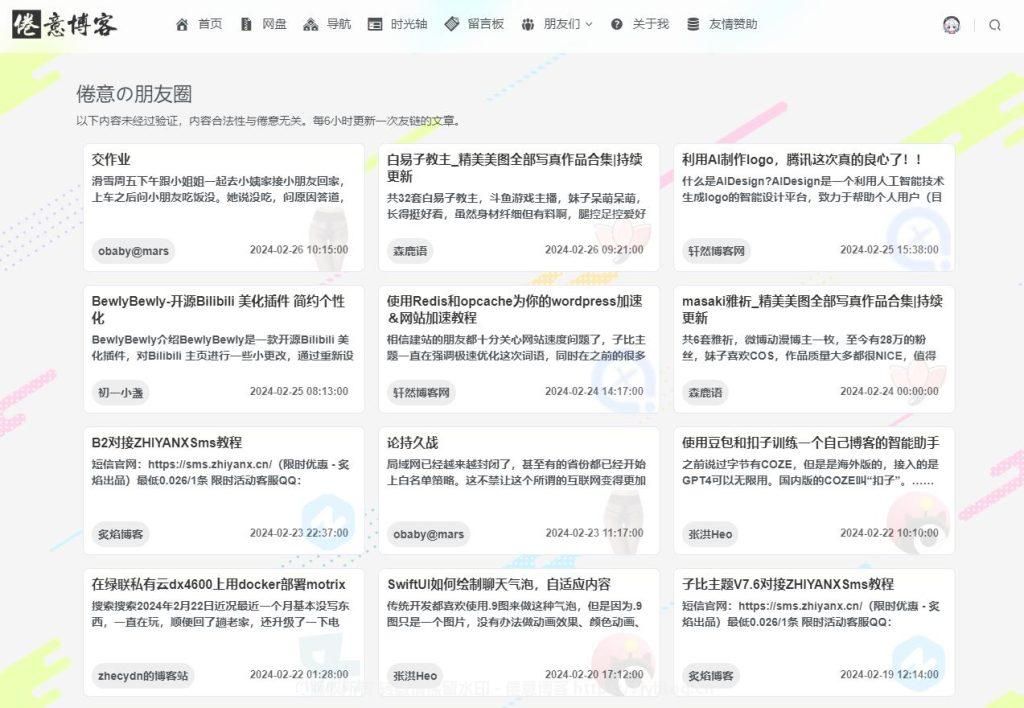
接下里我讲一下部署方法:
1.部署FreshRSS:
在Github上下载FreshRSS的最新版
https://github.com/FreshRSS/FreshRSS
因为我是用宝塔,所以接下来都是在宝塔上实现,其他运维软件请自行寻找对应方法
在宝塔上新建一个网站,这里不需要创建数据库,因为我们在后面要使用SQLite󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
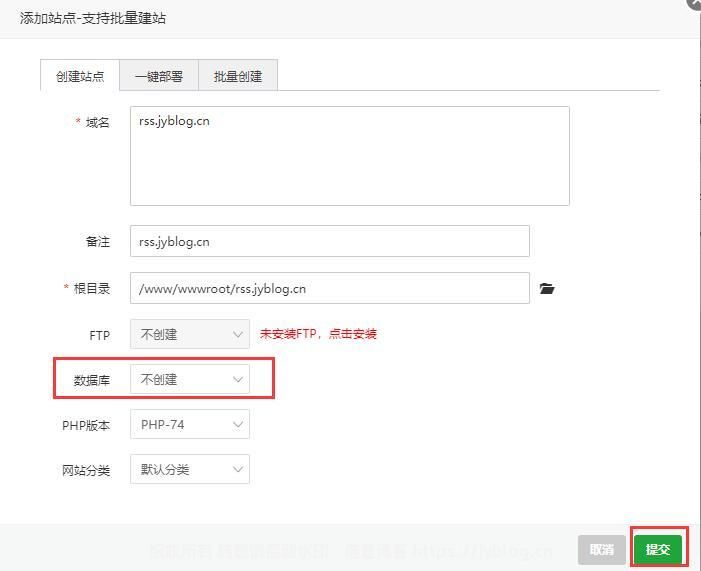
并将刚刚下载的FreshRSS解压到目录里面去
在PHP设置中,安装fileinfo扩展󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮

打开网站,我们开始根据提示安装
这里唯一要注意的是数据库配置里面要选择SQLite󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
2.配置FreshRSS
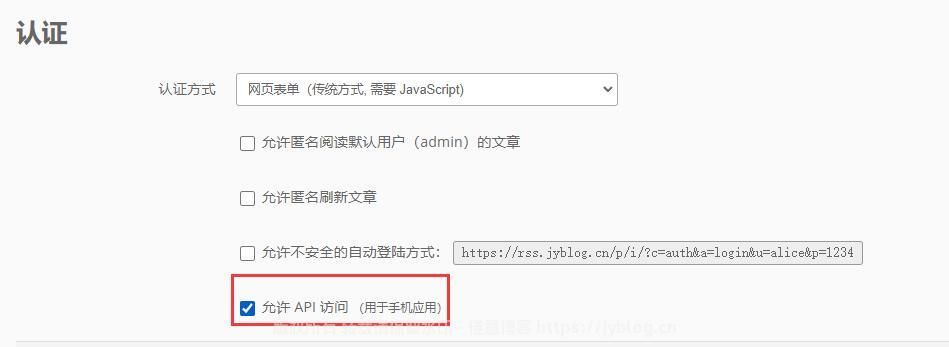
搭建好之后,登陆进去之后【设置->管理->认证】去开启允许api
进入【设置->账户->账户管理->API 管理】设置密码并提交保存,记住设置的api密码
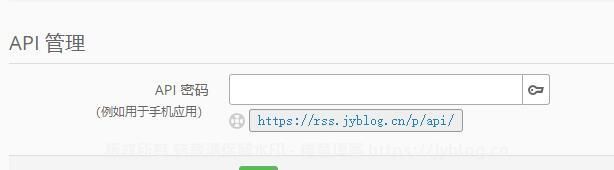
我们点进去下面这个链接,保存你的API地址

3.配置爬虫文件
请确保您已经正确安装Python,一般宝塔自带Python,没安装参考下:https://jyblog.cn/963
在网站目录下创建一个spider.py文件,写入以下代码:󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
(爬虫文件作者obaby,项目链接:https://github.com/obaby/Baby-Freshrss-Client)
import json
import time
import html2text
import requests
from bs4 import BeautifulSoup
from pyfiglet import Figlet
FRESHRSS_HOST = 'http://freshrss.h4ck.org.cn' #不带最后的/
USERNAME = 'obaby'
PASSWD = '1234567890'
labels = ['集美们'] # 输出的订阅标签list
WRITE_TO_FILE_COUNT = 60
SUB_MAX_ITEMS_COUNT = 2
JSON_FILE_PATH = '/home/wwwroot/h4ck.org.cn/rss.json'
def print_hi(name):
print('*' * 100)
# f = Figlet(font='slant')
f = Figlet()
print(f.renderText('obaby@mars'))
print('FreshRss Client')
print('Verson: 23.12.24')
print('闺蜜圈:https://dayi.ma')
print('Blog: http://oba.by')
print('欢迎帮姐姐推广闺蜜圈啊')
print('*' * 100)
def get_token():
print('[*] Login to get token.')
resp = requests.get(FRESHRSS_HOST+'/api/greader.php/accounts/ClientLogin?Email='+USERNAME+'&Passwd='+ PASSWD).text
# print(resp)
token = resp.split('Auth=')[1].replace('r','').replace('n','')
print('[*] Token =',token)
print('[*] ', '-'*100 )
return token
def get_rss_items_list(token):
heaers = {
"Authorization":"GoogleLogin auth=" +token,
"Accept-Encoding":"gzip, deflate",
"User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; Tablet PC 2.0; wbx 1.0.0; wbxapp 1.0.0; Zoom 3.6.0)",
}
resp = requests.get(FRESHRSS_HOST+'/api/greader.php/reader/api/0/stream/contents/reading-list?n=99999999999&output=json', headers=heaers).text
# print(resp)
return resp
def get_rss_addr_list(token):
heaers = {
"Authorization": "GoogleLogin auth=" + token,
"User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; Tablet PC 2.0; wbx 1.0.0; wbxapp 1.0.0; Zoom 3.6.0)",
}
resp = requests.get(
FRESHRSS_HOST+'/api/greader.php/reader/api/0/subscription/list?output=json&n=10000',
headers=heaers).text
# print(resp)
return resp
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_hi('obaby')
token = get_token()
# body=get_rss_items_list(token)
addr_list = get_rss_addr_list(token)
ajs = json.loads(addr_list)
# print(ajs)
subs = ajs['subscriptions']
print('[*] All subscriptions=',len(subs) )
selected_usb = {}
for s in subs:
cats = s['categories']
for c in cats:
if c['label'] in labels:
# sd = {s['id']:{
# 'title':s['title'],
# 'iconUrl':s['iconUrl']
# }}
selected_usb[s['id']]={
'title':s['title'],
'iconUrl':s['iconUrl']
}
# print(selected_usb)
print('[*] Selected label subscriptions=', len(selected_usb))
body = get_rss_items_list(token)
js = json.loads(body)
print('[*] Total rss item count=',len(js['items']))
sub_count_list = {}
items = js['items']
items = sorted(items, key = lambda item:item['published'], reverse=True)
formated_item = []
for i in items:
string_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(i['published']))
# content = html2text.html2text(i['summary']['content'])
soup = BeautifulSoup(i['summary']['content'], 'html.parser')
content = soup.get_text()
content = content.replace('r','').replace('n','')[:100] + '……'
stream_id = i['origin']['streamId']
if not stream_id in selected_usb.keys():
# print(stream_id)
continue
ni = {
"site_name": i['origin']['title'],
"title": i['title'],
"link": i['alternate'][0]['href'],
"time": string_time,
"description": content,
"icon": selected_usb[i['origin']['streamId']]['iconUrl'],
"published":i['published']
}
# formated_item.append(ni)
if stream_id in sub_count_list.keys():
if sub_count_list[stream_id] >=SUB_MAX_ITEMS_COUNT:
continue
else:
formated_item.append(ni)
sub_count_list[stream_id] += 1
else:
formated_item.append(ni)
sub_count_list[stream_id] =1
# print(formated_item)
# print(len(formated_item))
print('[*] Selected labeled rss item count=',len(js['items']))
print('[*] Write json to file......')
for ff in formated_item:
print(ff['time'], ff['title'])
with open(JSON_FILE_PATH, 'w',encoding='utf8') as f:
# 使用json.dump()函数将序列化后的JSON格式的数据写入到文件中
json.dump(formated_item[:WRITE_TO_FILE_COUNT], f, indent=4,ensure_ascii=False)
print('[*] Write json to file done')
print('[*] Write to file items count=', WRITE_TO_FILE_COUNT)
print('[*] Sub items max count=', SUB_MAX_ITEMS_COUNT)
print('[*] All finished.')
print('~' * 200)FRESHRSS_HOST = 'https://rss.jyblog.cn/p' RSSApi地址,填写第二步保存的api地址,后面的api/greader.php不用填写USERNAME = 'juanyiblog' 后台的用户名PASSWD = ' 第二步设置的api密码,注意是api密码不是后台密码juanyiblog'labels = ['朋友圈'] 订阅的分类WRITE_TO_FILE_COUNT = 60 # 最后写入到json文件的订阅数量SUB_MAX_ITEMS_COUNT = 2 # 每个站点最多展示的条目JSON_FILE_PATH = 'juanyi.json' 输出的json文件路径配置,请放到网站目录下
4.运行爬虫文件
安装必要的运行库文件:
pip install Figlet
pip install BeautifulSoup
pip install requests
pip install html2text试着去执行一遍。反正缺什么补什么
在计划任务中加入以下代码:󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
cd 填写你的网站绝对地址
php app/actualize_script.php
python spider.py多少小时执行一次看你心情
5.在你的网站上显示
这里我做了一个小插件,可以很方便的配置,省了很多事情!
将文件丢到WordPress插件目录下,后台启动插件。󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
请勿盗卖资源/修改作者信息再发布,尊重原创活力。
盗卖只会扼杀创作热情,最终无人创作,也无资源可卖。
侵权账号将永久封禁且不接受申诉!
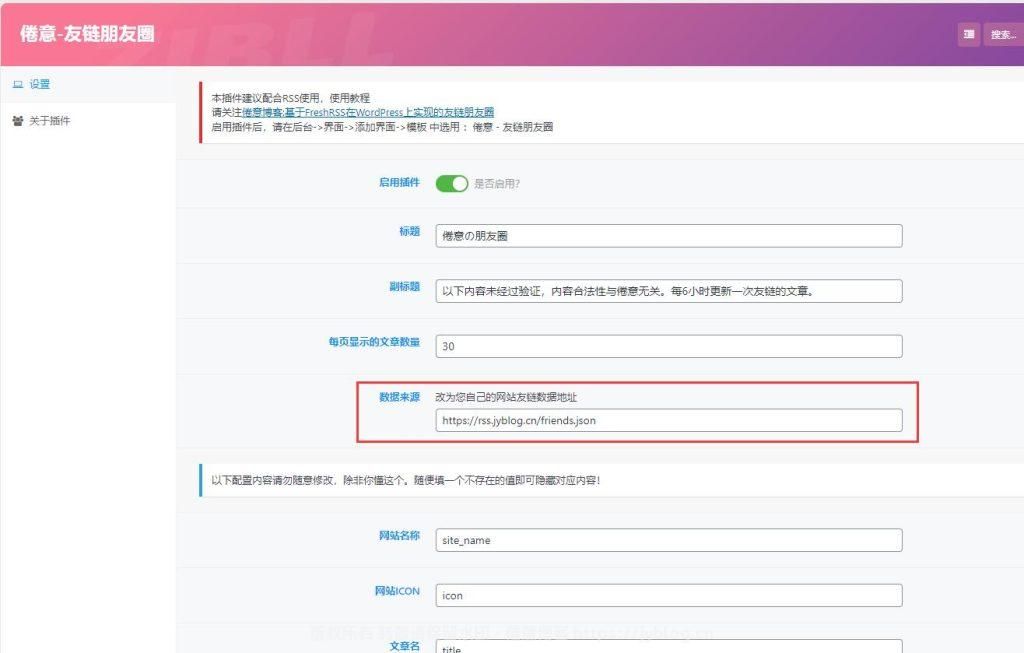
启动插件后,将 第三步配置好的 JSON_FILE_PATH JSON文件输出路径写入,保存!
然后再后台->界面->添加界面->模板 中选用 :倦意 - 友链朋友圈󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
Enjoy!
鸣谢:
我站在了以下大佬的肩膀上: 朋友圈的布局CSS参考自张洪大佬的鱼塘(https://blog.zhheo.com/moments/)
爬虫脚本obaby写的 (https://h4ck.org.cn/2023/12/14859) 󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
FreshRSS部署方法参考自若志(https://www.rz.sb/archives/228/) 󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄤󠄦󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄦󠄩󠄨󠄤󠄢󠄣󠄡󠄡󠄬󠅒󠅢󠄟󠄮
感谢以上大佬的无私奉献



 捐助名单
捐助名单
 *嘢
*嘢
 *静
*静
 *羊
*羊

参与讨论